AI & Linked Open Data for Innovation in Extension
AI & Linked Open Data for Innovation in Extension
Justin G. Smith
Assistant Professor, Community & Economic Development
Washington State University
Big Data & Artificial Intelligence
Two of the biggest topics in technology today are big data and artificial intelligence (machine learning and deep learning). Data is growing exponentially, and according to IDC, the digital universe will double every two years from 2010 to 2020. This includes satellite imagery data, sensor and mobile data (IoT), banking and economic data, as well as health and genetic research data. Businesses are also generating massive data sets related to supply-chain operations, and customer purchase patterns, while governments and non-governmental organizations around the world collect and publish information about population demographics, economic indicators, environmental quality and health outcomes.

In many cases these data are open to the public, Given the increased accessibility of data, we have seen rapid development in the field of artificial intelligence. The synergy between big data and new data analytics methods are leading to a new cognitive technologies that give people power to improve (and even automate) decision-making and optimize outcomes. This powerful combination is leading to breakthroughs in medicine, finance, transportation, operations, security and law enforcement, as well as food and agriculture. In particular, there are a growing number of case studies highlighting improvements in a broad range of decision-support functions such as fraud detection, recommendation systems, medical diagnostic systems, and now driverless vehicles, and precision agriculture.
Linked Data, AI & the Semantic Web
These advancements would not be likely if it weren’t for the openness and accessibility of structured data; applications that utilize machine learning or ‘deep learning’ techniques often require significant amounts of data to develop accurate models. In particular, the proliferation of Linked Open Data tools (RDFa, JSON-LD, Microformats), common vocabularies (Schema.org, Linked Open Vocabularies), and APIs (web-services) have contributed significantly to the pace of development of new smart systems by providing access to structured data. Consequently, the success of AI powered by big “linked” data, has incentivized the adoption of standards and new publishing practices such as OpenAPI, leading to a growing network of accessible data services from which to explore and solve new problems.
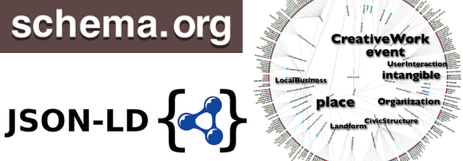
The relationship between structured data and intelligent machines on the Internet was suggested nearly 20 years ago, by Tim Berners Lee and his colleges at CERN. In 2001, Berners Lee, Hendler and Lassila published a paper titled the “Semantic Web”, where they described a network of structured data, semantically linked together, and encoded in standard formats readable to both people and machines. Since then, the development of semantic web technologies, and more recently Linked Open Data have accelerated, creating new opportunities for organizations to access and use data in new ways.
Cognitive Systems and the Possibility of a Virtual Extension
The number of new decision-support technologies (or cognitive systems) is astonishing, and new platforms are coming online every month. This trend inspired my own thinking. I wondered, what could our Extension systems create. What if we could develop cognitive technology that could access and use the knowledge resources from Extension across the country to help communities and families adapt to climate change or improve household food security? What if the same technology could connect people to the experts across the county that could help them solve real challenges? Or perhaps the tool could provide small farmers answers to questions about fertility management, integrated pest management, or food preservation?
Virtual Assistant – Interactions between Data, Devices and People
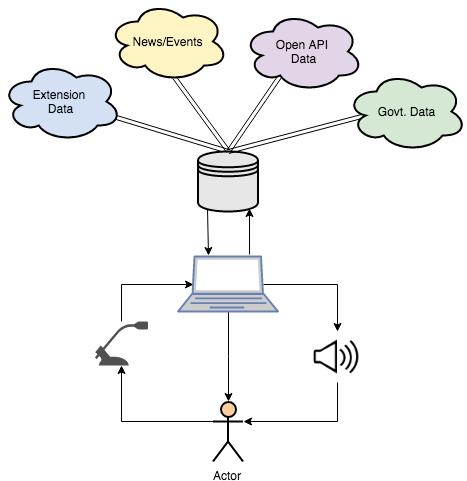
For a moment, I imagined what it would be like to interact with a virtual assistant like Alexa, to be able to ask questions, find experts, or even conduct a collaborative strategy meeting where a virtual assistant acts as a kind of facilitator that collects and displays data, or walk a group through a sequence of planning tasks. I imagined teams of professionals in the counties I work conducting SWOT analysis, policy mapping, or testing climate change mitigation and recovery strategies. Such a system could interface with augmented reality tools that support problem-solving in situ with a mobile device. I could see our clients working in new ways while leveraging the knowledge and expertise of Extension and Land Grant Universities all across the country.
For many of my Extension colleagues, this all sounds like science fiction, or in the very least wildly ambitious. Ambitious is probably true, but it is definitely not science fiction. In addition to the proliferation of open structured data, the new API economy is creating access to services, allowing developers to connect to third-party applications and data to create new products.
Google, Microsoft, IBM, and Amazon all offer access to their computing infrastructure and machine learning services. Moreover, an active community of developers both within and outside these companies are generating the documentation, examples and materials needed to uses these services (see: Flask-Ask). Using these APIs we can integrate Alexa Skills, Google Speech API and our own custom set of interactions, essentially creating entirely new services. Many of the foundational technologies have been established to help us develop our virtual assistant. We don’t even have to worry about training a model for voice recognition before getting started. Teams of researchers and developers at Google, IBM, and Amazon are already working on providing the services that can help us get a minimal prototype up and running.
Now we know some of the basic tools are in place to make our virtual assistant a reality, and we can explore the idea further. So what’s next? For sake of simplicity, let’s say we are willing to use Amazon’s Alexa service. Next, we would need to define a set of use-cases, prototypical sequence of interactions. For instance, we could define a strategic planning protocol, that simulate a brainstorming session to allow small groups to organize ideas, collect and display data. We might also define an ‘expert-finder ’ protocol, or a search and data aggregation protocol where each interaction process extends the overall functionality of the ‘assistant.’
Extension Data Products
In each use-case we are tasked with mapping a spoken or written request to a relevant and accurate spoken and/or visual digital response. In this context the digital response utilizes Extension experts and Extension research assets.
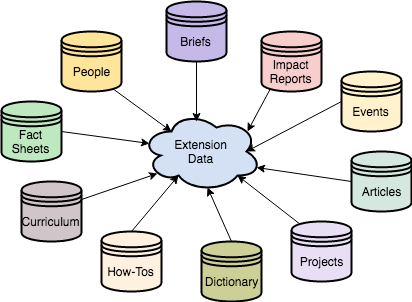
The (Structured) Data Challenge
Using these assets requires the ability to collect structured data from among a diversity of data types (e.g. Briefs, Factsheets, etc.), and service providers (the universities). This presents the first major challenge. For the most part, Extension’s resources are not available in a structured form. Some content providers do use a combination of Schema.org and Open Graph formats already, allowing some access to generic content descriptions, such as titles, type description and occasionally content authors and summaries. These provide useful metadata for content searches, but are not expressive or precise enough to run more complex queries and interactions. However, both Schema,org and the Open Graph protocol offer access to a rich vocabulary that can be extended to include different data types (or used with existing vocabularies), and these tools allow us to describe these data from within HTML web content.
This is crucial as developing our virtual assistant as we will need access to the embedded content within Extension research products. This includes identifying and encoding both generic descriptions (e.g. summaries and keywords), as well as embedded data (e.g. processes, methods, numeric data) across a range of content such as impact reports, curriculum, research articles, and technical reports. The more embedded snippets of content can be exposed, the more information and behaviors we can code into our virtual assistant.
However, this is more difficult than it would appear. Extension systems manages their digital assets differently (different policies and technology platforms) and separately. There is no ‘complete’ central directory of Extension faculty listing their expertise, and among the directories that exist, they often lack additional information about a person other than name, rank and department. Moreover, there is no agreed upon vocabulary that could be used to describe these resources. The necessary enabling technologies and standardized institutional practices are missing.
The lack of critical infrastructure or adoption of Linked Data practices presents a significant hurdle, one that will need to be resolved before our virtual assistant can be successful. Filling the current capacity gap would require the kinds of recommendations laid out by Jeff Piestrak’s vision for a Land Grant Informatics.
Extension Knowledge Network
This includes the development of common vocabularies or ontologies relevant to Extension. This also includes the adoption of new publishing tools that enable embedded tagging of people, places, things and events, as well as ways to link these together across institutions.
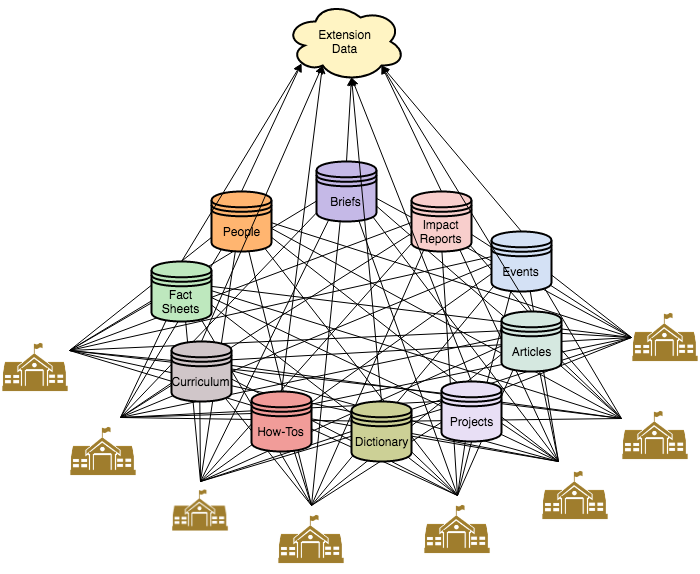
Before we can develop our virtual assistant, we need to define an ontology, or type of vocabulary for describing a much richer set of data, and then devise a strategy for describing existing Extension assets using that ontology. This of course is no trivial task. To ensure the ontology is useful would likely require broad participation and buy-in from Extension faculty across the country, and then, we still need to go back through all of the historical databases and describe these resources.
The more you dive into it, the more challenging this virtual assistant project sounds. Yet, this challenge is not exclusive to building a virtual assistant. A vast majority of modern web applications rely on accessible third-party services, data and ontologies to develop new products, but without a roadmap (for Extension) to connect it all together and no common language for interacting with the content, we find ourselves confronted by a kind of virtual wall. So it seems that in order to build my new ‘killer-app,’ I will first need to solve the ontology problem, and based on what I’ve describe so far it sounds like it could take a decade to complete. Unfortunately, I am not all that patient. I cannot wait 10 years for this to be resolved, nor can my clients. So what now?
In Need of a Different Approach
Well, there might be a solution, are at least a bridge to a solution. What if we turned a few implicit assumptions on their heads? Up to this point I’ve talked about structured linked-data as the required input for training a machine learning model. This type of approach to machine learning is called supervised learning. In a supervised learning situation, the algorithm approximates a prediction about some data based on previous data. In this case, we feed a structured data set to our algorithm to develop a model or representation of the data that we then use to interpret any new data.
What if that isn’t the complete story? What if we could use machines to learn and create ontologies readable to humans, and usable by other machines? Or what if we could use machines to create semantic links between content, and then offer access to these data through accessible API services? Developments in natural language processing, and computer vision suggest the possibility that we could indeed use machines to generate structures that could be useful in our virtual assistant (or any other application). Semi-supervised and unsupervised machine learning allow for structured data to be pulled directly from data with little or no upfront input needed. There are a growing number of examples with AI being used to create content, such as music or art, content summaries, as well as image and video content. Considering these developments, it seems reasonable that AI could be used to describe and encode our content just as easily as it is being used to create fake news, or conversely, combat fake news.
In 2016, eXtension and GODAN teamed up to sponsor a joint fellowship to explore these questions and develop pathways for creating the ontologies that would link Extension to the larger universe of linked open data. In particular, their request focused on developing ontologies, methods and recommendations that could be used to link Extension data to address challenges around climate change adaptation and food insecurity. This included exploring the possibility of using competency frameworks and design patterns to define a set of ontologies that could be used to describe various eXtension content. Together, these frameworks provide a vocabulary for defining skills, knowledge, resources, problems, contexts and solutions — enough new metadata that could prove expressive enough to power a virtual assistant or similar applications.
Later that year, eXtension and GODAN, gave me an opportunity begin exploring these questions. In October, I began work on several experiments to determine the efficacy of machine learning and AI technologies to create structured data from eXtension content. I worked with eXtension fellow Christian Schmieder from University of Wisconsin Cooperative Extension, and colleagues at Washington State University to develop and test new methods and algorithms that could be used generate ontologies and automatically markup resources using RDFa and JSON-LD.
During the following 18 months, I embarked on an incredible (and difficult) journey of learning and discovery that profoundly changed my life. This experience revealed new passions in design, natural language processing, decision analysis, algebraic topology and cognitive technology. The fellowship also thrust me into a new field of scientific inquiry with a rather steep learning curve, and I found myself immersed in the language of graphs, networks, matrices and probability distributions – the basic building blocks of modern AI. In all of this learning, I was given a platform to develop new approaches to AI that incorporated existing state-of-the-art with more recent developments in reinforcement learning and topological data analysis. The result was a set of methods and tools with broad application in content classification and organization, but also in complex systems analysis, multicriteria decision-analysis and optimization.
Over the next several weeks I will be sharing the process and results of these experiments through a series of blog posts, tutorials and open source software. In each post I will walk through the challenge of developing a usable vocabulary that can serve our hypothetical virtual assistant. I will also be posting a series of scientific notebooks that show how these systems work (or don’t work), discuss opportunities and remaining challenges.
For More Information
For more information, contact Dr. Justin Smith at:
justingriffis@wsu.edu
